Architecture¶
This section details the Tigres architecture. In this section, Tigres data types and their relationships with one another, a high-level overview of the major Tigres components and how they interact and the special Tigres syntax that allows you to explicitly specify data dependencies between workflow tasks is discussed.
Data Model¶
This section describes the Tigres data model concepts.
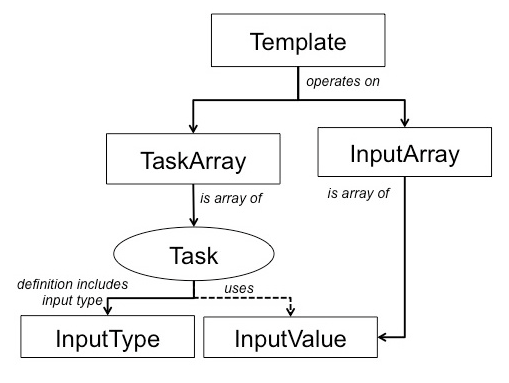
A Template takes a TaskArray, that is a collection of tasks to be executed together, and an InputArray with the corresponding inputs to the tasks. The elements in a TaskArray form a collection of tasks that need to execute either in a sequence or in parallel.
Each Task definition includes the InputTypes that defines the type of inputs that the task takes. The InputArray is a collection of InputValues. InputValues are the values that are inputs to the task and its types match what is defined in the InputTypes. InputValues are passed to the task during execution and not included in the task definition. This allows for reuse of task definitions and late binding of actual data elements to the workflow execution.
Tigres uses a special syntax called PREVIOUS syntax to create data dependencies between tasks.
Using tigres.PREVIOUS the user can specify the output of a previously executed task as input for a subsequent task.
Not only can PREVIOUS create data dependencies between tasks, it can also span across templates.
Note
PREVIOUS can be both implicit and explicit. The semantics of PREVIOUS are affected by the template type.
Implicit PREVIOUS¶
PREVIOUS is implicit when there are no input values for a task execution. Below are the four Tigres templates
with an explanation of how PREVIOUS is handled implicitly for each.
| sequence: | If input values for any of the tasks are missing, use the entire output of the previous task or template.
|
|---|---|
| parallel: | If the following conditions are met:
a) no inputs are given to the parallel task (input_array)
b) the results of the previous template or task is iterable
c) there is only one parallel task in the task_array
then each item of the iterable results becomes a parallel task.
|
| split: | If the split task is missing input values use the output from the previous task or template.
If parallel tasks are missing input, semantics of the parallel template are used.
|
| merge: | If merge task missing input values use all outputs of the previous parallel tasks.
If parallel tasks are missing input, semantics of the parallel template are used.
|
Explicit PREVIOUS¶
PREVIOUS is explicit when the following syntax is used as input in InputValues
PREVIOUSPREVIOUS.iPREVIOUS.i[n]PREVIOUS.taskOrTemplateNamePREVIOUS.taskOrTemplateName.iPREVIOUS.taskOrTemplateName.i[n]
Below are the valid usages of PREVIOUS. It must be passed as a single value in an InputValues and it
is evaluated immediately before the execution of the Task it is paired with.
PREVIOUS¶
Use the entire output of the previous task as the input.
| Valid Usage: | InputValues([PREVIOUS]) |
|---|---|
| Validation: | Did this task already run?
Are there results?
|
PREVIOUS.i¶
Used to split outputs across parallel tasks from the previous task.It matches the i-th output of the previous task/template to the i-th InputValues of the task to be run. This only works for parallel tasks.
| Valid Usage: | InputValues([PREVIOUS.i, PREVIOUS.i, ...]) |
|---|---|
| Validation: | Did this task already run?
Are there results?
|
PREVIOUS.i[n]¶
Use the n-th output of the previous task or template as input.
| Valid Usage: | InputValues([PREVIOUS.i[n]) |
|---|---|
| Validation: | Did this task already run?
Are there results?
|
PREVIOUS.task¶
Use the entire output of the previous template/task with specified name.
| Valid Usage: | InputValues([PREVIOUS.taskOrTemplateName]) |
|---|---|
| Validation: | Does the named task or template exist?
Did this task already run?
Are there results?
|
PREVIOUS.task.i¶
Used to split outputs from the specified task or template across parallel tasks. Match the i-th output of the previous task/template to the i-th InputValues of the task to be run. This only works for parallel tasks.
| Valid Usage: | InputValues([PREVIOUS.taskOrTemplateName.i, PREVIOUS.taskOrTemplateName.i, ...]) |
|---|---|
| Validation: | Does the named task or template exist?
Did this task already run?
Are there results?
Are the results indexable?
|
PREVIOUS.task.i[n]¶
Use the n-th output of the previous task or template as input.
| Valid Usage: | InputValues([PREVIOUS.taskOrTemplateName.i[n]]) |
|---|---|
| Validation: | Does the named task or template exist?
Did this task already run?
Are there results? Are the results indexable?
|
System Components¶
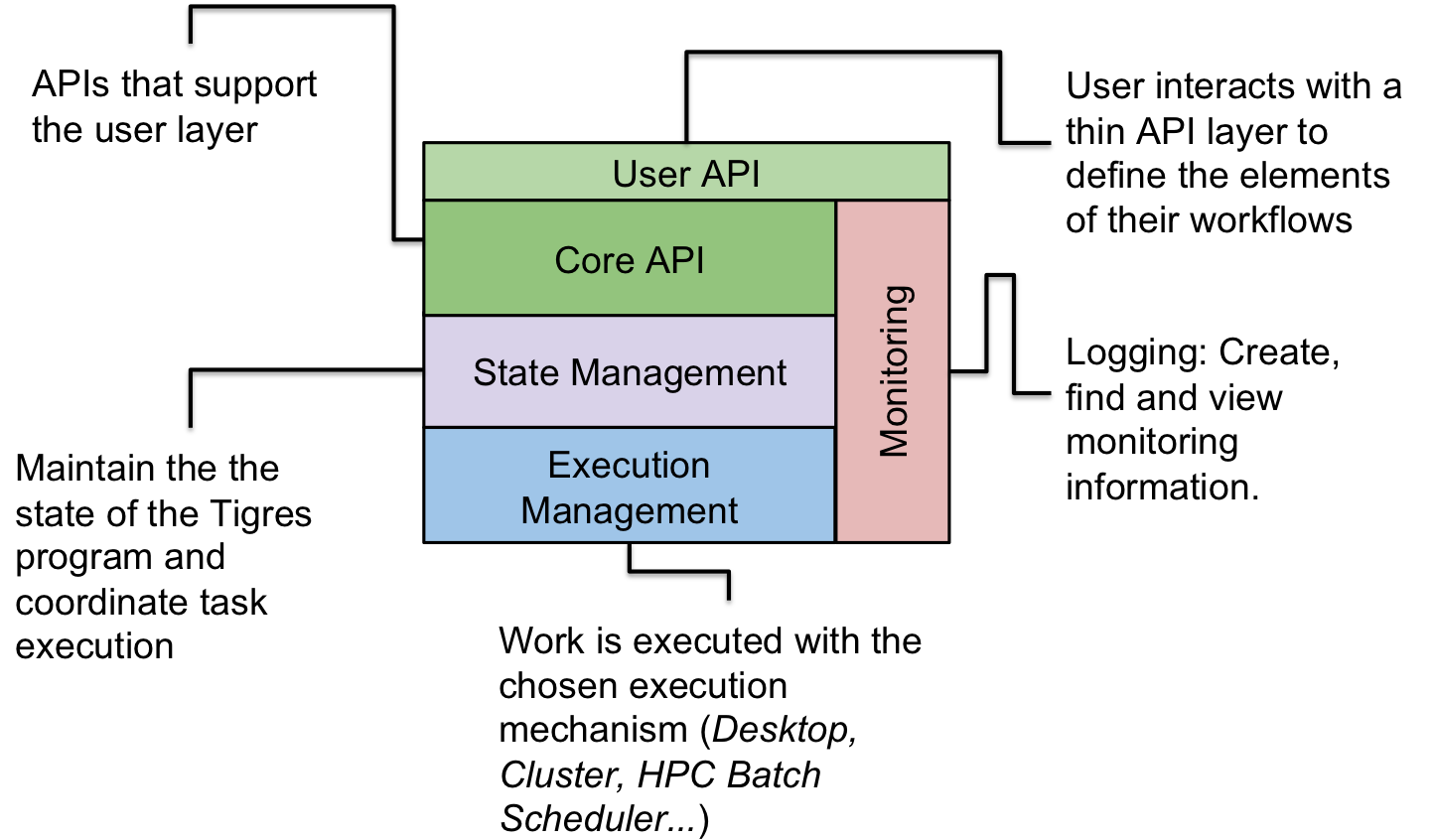
Tigres has five major components in a layered architecture: User API, Core API, State Management, Execution Management and Monitoring. The top most layer, the User API, is directly supported by Monitoring and Core API components. The execution type semantics is managed deeper down the stack by State and Execution Management components.
The user interacts with a thin User API to define the elements of their workflows, log messages and monitor their program execution. The core API is a collections of interfaces that support the User API with graphing, creating tasks, managing task dependencies and running templates. Monitoring is used by most other components to log system or user-defined events and to monitor the program with a set of entities for querying those events.
State management encompasses different execution management aspects of the workflow. For instance, it validates the user input to confirm they result in a valid workflow both prior to start as well as during execution. It transforms the Tigres tasks into Work that are then handed off to execution management. The state management layer also provides monitoring and provenance capabilities. It maintains state as each template is invoked and integrity of the running Tigres program.
The execution layer can work with one or more resource management techniques including HPC and cloud environments. In addition, the separation of the API and the execution layer allows us to leverage different existing workflow execution tools while providing a native programming interface to the user.
Monitoring¶
Monitoring information in Tigres is produced at two levels: system and user. All timestamped log events are captured in a single location (a file). The user is provided with an API for creating user-level events, checking for the status of tasks or templates and searching the logs with a special query syntax. System-level events provide information about the state of a program such as when a particular task started or what is it’s latest status (e.g. did a task fail?).
User Level Logging¶
One of the design goals of the state management is to cleanly combine user-defined logs, e.g. about what is happening in the application, and the automatic logs from the execution system. The user-defined logging uses the familiar set of functions. Information is logged as a Python dict of key/value pairs. It is certainly possible to log English sentences, but breaking up the information into a more structured form will simplify querying for it later.
The following functions create log events at the specified log level. They are all
wrappers around tigres.write().
Here is an example of creating trace level log events from within a function which details the input and output values.
def salutation(greeting, name):
"""
:param greeting: A greeting
:param name: The name to greet
:return: personalized greeting or salutation
"""
log_trace('input', function='salutation', message='greeting={}, name={}'.format(greeting, name))
output = "{} {}".format(greeting, name)
log_trace('output', function='salutation', message=output)
return output
System Level Logging¶
The Tigres system may be monitored using tigres.check() and tigres.query().
A user may check the latest status of a program, task or template:
task_check = check('task', state=State.FAIL)
for task_record in task_check:
print(".. State of {} = {} - {}".format(task_record.name,
task_record.state,
task_record.errmsg))
Query gives the ability to filter log events by arbitrary key/value pair(s).:
# Check the logs for the decode event
log_records = query(spec=["event = input"])
for record in log_records:
print(".. decoded {}".format(record.message))
Execution Management¶
A Tigres program may be written once and run multiple times on different resource systems. The execution engine is specified at run time. A Tigres program can be executed on your personal desktop with local threads or processes. It can also be distributed across a cluster of nodes. Additionally, if you have access to a batch job scheduler, Tigres can use that. The interchangeability of different execution mechanisms allows you to develop your analysis on a desktop or laptop and scale it up to a department clusters or HPC centers when your code is ready for production without actually changing the workflow code.
The different Tigres execution plugins require minimal setup. The plugins can be classified as desktop (single node), cluster and job manager execution plugins. Each execution plugin has its own mechanism for executing tasks as well as parallelization.
| Type | Name | Execution Mechanism | Parallelization |
|---|---|---|---|
| Desktop | Local Thread
Local Process
|
Threads
Processes
|
Local Worker Queue
Local Worker Queue
|
| Cluster | Distribute Process
|
Processes
|
Task Server and Task Clients
|
| Job Manager | SGE
SLURM
|
SGE Job
SLURM Job
|
Sun Grid Engine (
qsub)SLURM (
squeue) |
Desktop Execution¶
There are two execution plugins for use on a single node: LOCAL_THREAD
and LOCAL_PROCESS. Both plugins behave similarly except that LOCAL_THREAD spawns
threads for each task while LOCAL_PROCESS spawns a process. The default
Tigres execution is LOCAL_THREAD. You change the execution mechanism
by passing in a keyword argument to tigres.start():
from tigres import start
from tigres.utils import Execution
start(execution=Execution.LOCAL_PROCESS)
...
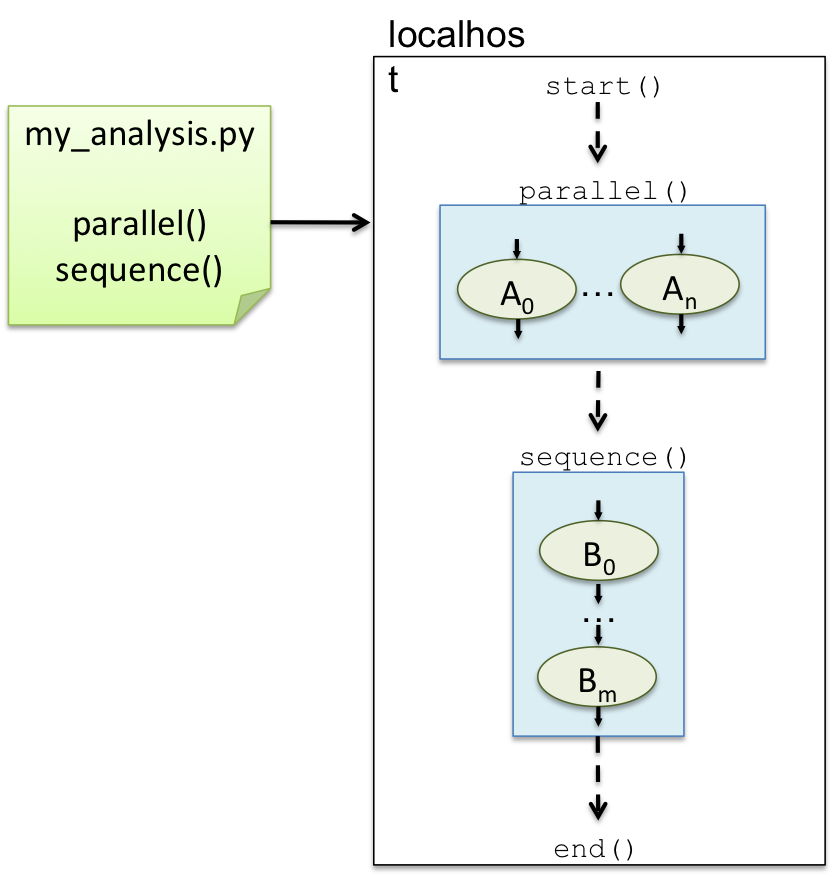
The figure to the right shows a simple Tigres program that launches n number of parallel tasks (A) and follows it up with a sequence of m tasks (B). This workflow is run on a single node (localhost).
Parallel execution is a very simple mechanism. All parallel tasks are placed in a worker queue, the number
of processing cores is determined and then a worker is spawned for each processing core. In the case
of local thread execution, the worker is a threading.Thread for local process
execution a multiprocessing.Process.
Cluster Execution¶
Running the Tigres program from above on a set of nodes in a local cluster takes a little more set up.
You change the execution plugin (Execution.LOCAL_PROCESS) and then set a one
or more environment variables.
DISTRIBUTE_PROCESS distributes tasks across user specified host machines. A
TaskServer is run in the main Tigres program. TigresClient`s, which run workers
that consume the tasks from the TaskServer, are launched on the
hosts specified in TIGRES_HOSTS environment variable . If no host machines
are specified, the TaskServer and a single TaskClient will be run on the local machine.
The Tigres program may have additional nodes configured with special environment variables:
TIGRES_HOSTS and OTIGRES_*.
TIGRES_HOSTS is a comma separated list of hosts names for distributing tasks.
(i. e. export TIGRES_HOSTS=n1,n2,n3). Additionally, any environment
variable prefixed with OTIGRES_ will be passed to the
TaskClient program on each node. For example, OTIGRES_PATH=tigres_home/bin
will be translated to the command PATH=tigres_home/bin; tigres-client which
is launched on the TaskClient nodes specified in TIGRES_HOSTS.
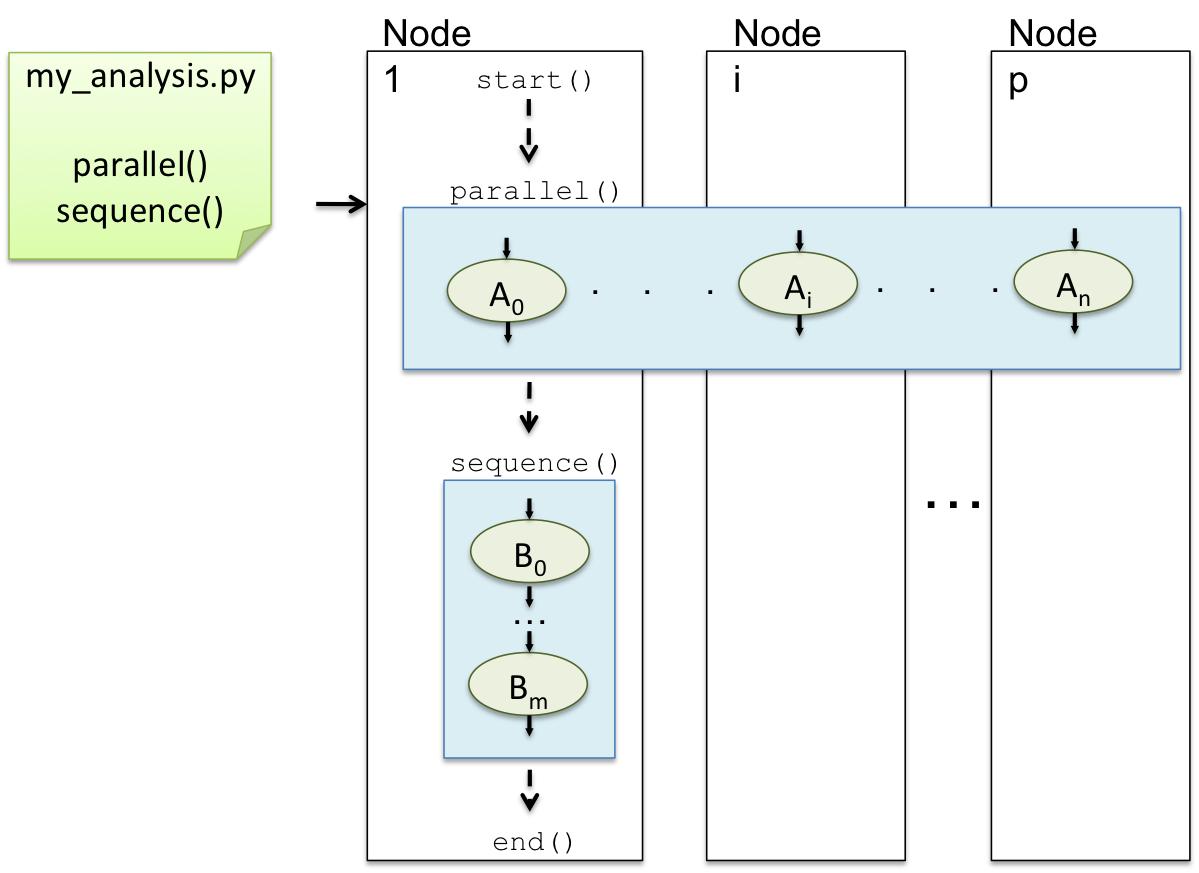
The figure above shows the same Tigres program as the previous figure. The program still has n parallel tasks and m sequential tasks but this time it is distributed across p nodes.:
localhost$ export TIGRES_HOSTS=node1,node2...nodep
localhost$ OTIGRES_PATH=tigres_home/bin my_analysis.py ...
The parallel template tasks are distributed across Node 1 through Node p.
The main Tigres program starts a TaskServer on Node 1 and then launches p TaskClients on
the nodes specified in TIGRES_HOSTS. The client programs run a process for each
processing core until the TaskServer runs out of tasks. The sequence template
tasks are run on Node 1 where the main Tigres program is executing.
Job Manager Execution¶
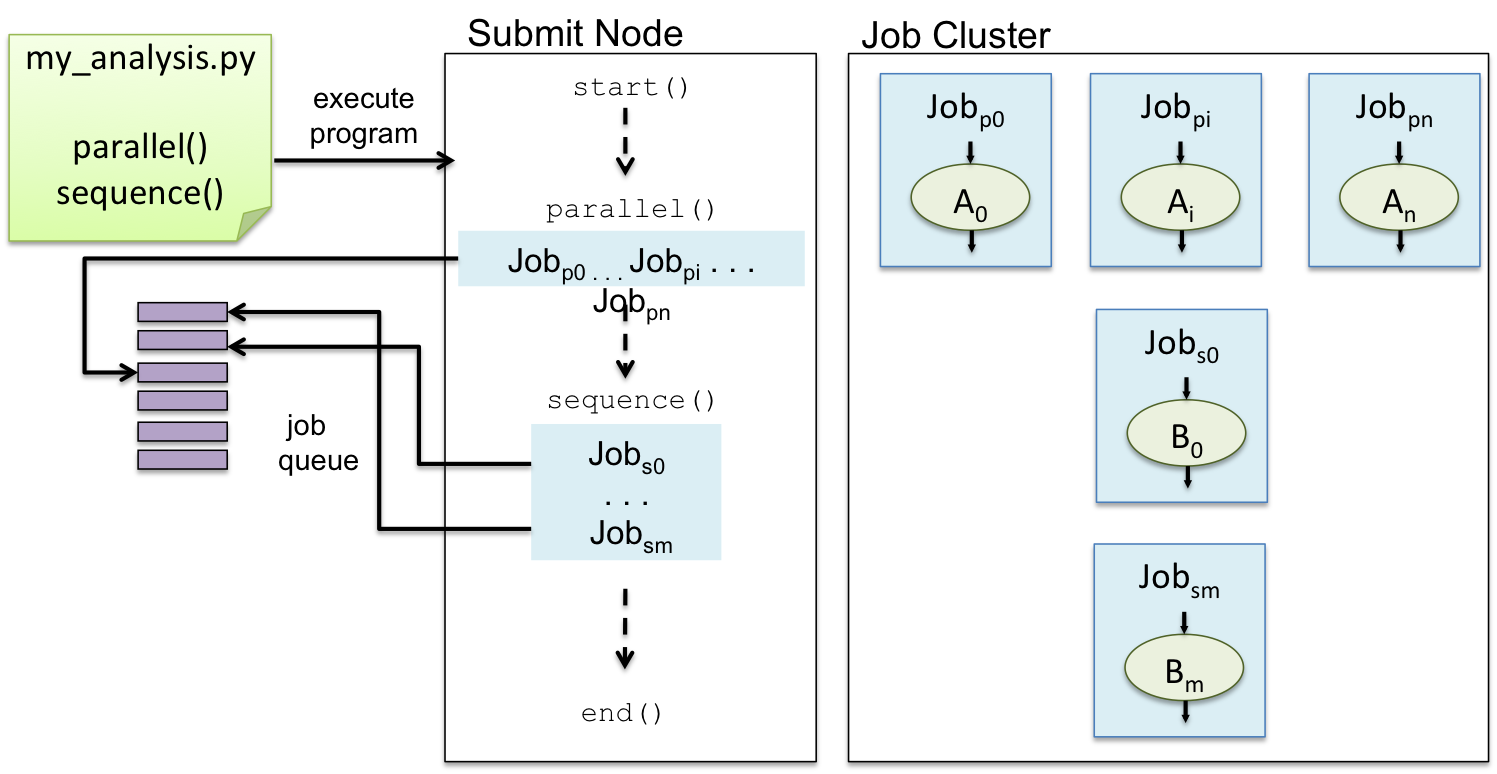
If you have access to resources managed by a job scheduler, Tigres supports Sun Grid Engine (SGE) and Simple Linux Utility for Resource Management (SLURM). Each task is executed as a job on the batch queue. Parallelism is managed by the job manager. Tigres submits all the jobs at the same time and then waits for completion.
The requirements for using a job manager execution mechanism are that you must have an account and the ability to load the Tigres python module. Of course the correct execution plugin must be chosen:
from tigres import start
from tigres.utils import Execution
start(execution=Execution.SGE)
...
The naive assumption is that you would be able to run your Tigres program from the submission node and have unfettered access to the queue. At National Energy Research Scientific Computing Center (NERSC), this is achieved with a resource reservation that provides a personal installation of SGE called MySGE.
In the figure above, my_analysis.py is run at scale with managed resources. The program is run on the node where
jobs are submitted to the batch queue. As with the other two examples, Desktop Execution and Cluster Execution, the
workflow first runs a parallel template with n tasks and follows it up with a sequence template of m tasks. The parallel
template submits n jobs simultaneously to the job manager. Upon their completion, the sequence template is executed. This
template submits one task job at a time and waits until it completes before the next one is submitted.
