Basic Templates Tutorial¶
The Tigres Python API allows you to compose a workflow as a python application. Tasks may be an executable or python function. In this tutorial, you will learn how to a) set up your Tigres environment, b) use each Tigres template, c) define data dependencies between tasks, d) log messages and e) query the tigres logs. For the sake of simplicity, the tasks in this tutorial will be python functions.
This tutorial uses three programs which can be found here in a file named tigres-0.1.1-tutorials.zip . Each program has the same final output but uses different methods to produce it. The example workflows chosen for this tutorial perform string manipulation. The example functions are intentionally kept simple for allowing us to focus on the Tigres components in this tutorial. Real world examples can be plugged in similarly with any of the Tigres templates
Before starting the tutorials, follow the Environment Setup instructions to prepare your environment for Tigres workflow execution.
Data Model and Execution¶
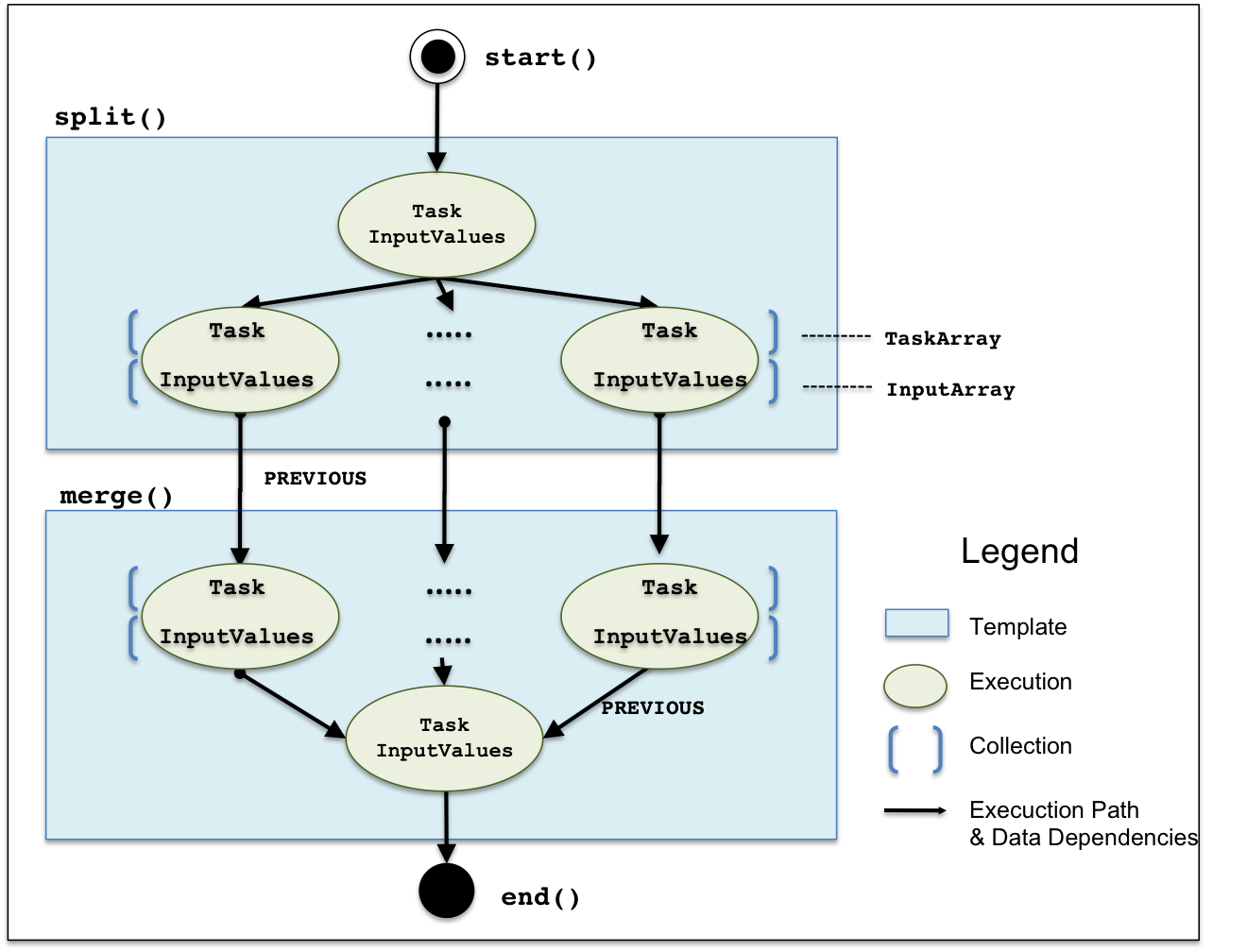
The Figure to the left shows the relationship of the Tigres Data Model to the workflow execution. The Split and Merge template tutorial is used here to illustrate how the Tigres API functions and data structures relate to the execution flow of a Tigres program.
All Tigres programs may optionally begin with start()
and finish with end() to initialize and finalize a Tigres program respectively.
The core of this workflow is a split() template followed by a
merge(). The (blue) boxes represent the templates and the (green) ovals inside are the
Tasks. The arrows simplistically signify the order of execution and data dependencies
between Tasks. The (blue) brackets indicate a collection (e.g. [Task .... Task] is collection
of tasks called a TaskArray)
The first template executed is a split (top box). It
requires four inputs: split_task, split_input_values, task_array, input_array.
The first execution (top green oval) in this template is the split_task which takes
split_input_values as input. Once this task completes it is followed by the parallel execution of the
tasks in the TaskArray, called task_array, paired with each
InputValues in the input_array.
The second template to be executed is a merge (bottom blue box). A merge is the mirror image of the split.
Its required inputs are: task_array, input_array, merge_task, merge_input_values.
The parallel execution (task_array, input_array) happens first followed by a single merge task
(merge_task, merge_input_values).
The data dependencies (blue dashed arrows) are specified by Tigres PREVIOUS. PREVIOUS is a syntax
where the user can specify that the output of a previously executed task as input for a task.
PREVIOUS creates dependencies between templates and can be either implicit
or explicit.
Parallel¶
(a parallel template example)
First we will use tigres.parallel(). In this example
(hello_world_parallel.py), which can be found in the zip
file here, we will take a coded string containing a hidden message as input,
decode the string using a parallel template and return the hidden message as output. Decoding the string with the parallel
template takes advantage of the processing cores available to the Tigres program. If there is only one processing core,
the string is decoded sequentially. However, if there are P processing cores where P > 1, then there will
be P parallel tasks used to decode the string. This Tigres program as well as the others in this tutorial
use a Program Skeleton.
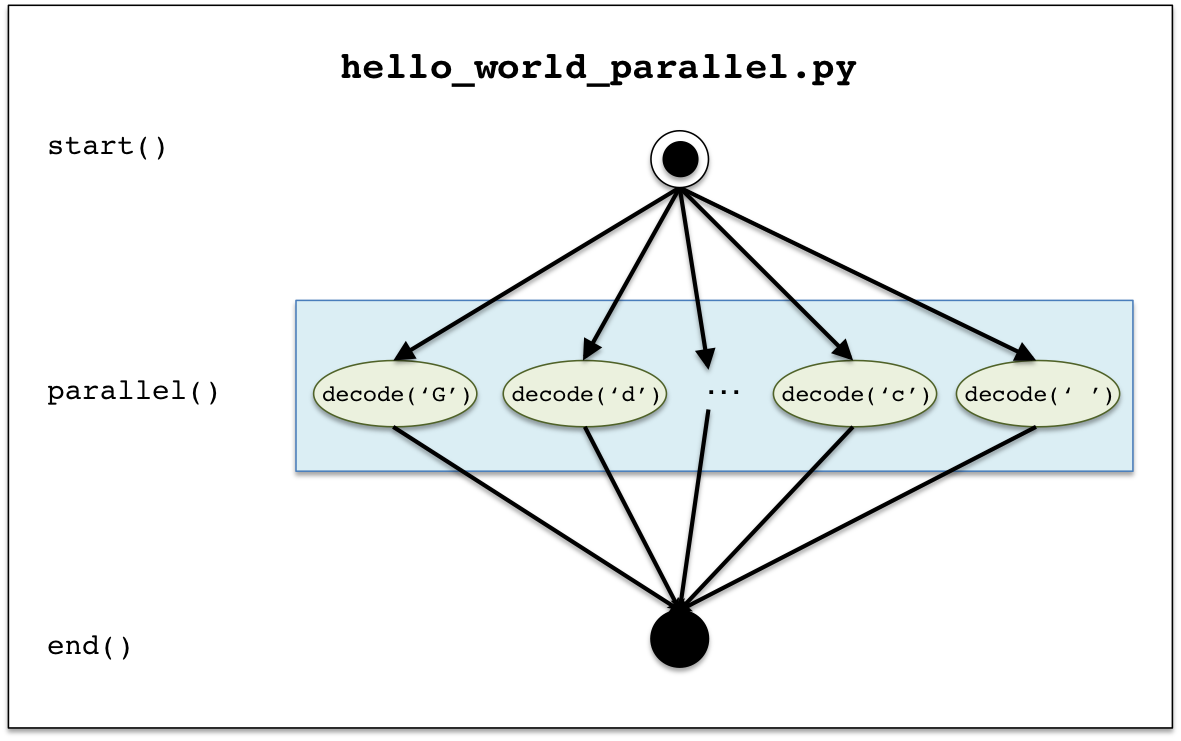
The coded string, "Gdkkn\x1fShfqdr\x1fvnqkc ", in hello_world_parallel.py is of length N and is
split into N tasks. There is one task for each character in the string. Each character will serve as input to a
python function, decode(). This function
will decode the string by adding one to the character’s ASCII code. For example, “G”
has an ASCII code of 71. If we added one to make it 72, the decoded character would be “H”.
If you haven’t done so already, follow the instructions in Environment Setup to setup your machine for
running Tigres programs. If you haven’t already downloaded the progams, download
hello_world_parallel.py, to the machine you will be running your
Tigres programs on. You are now ready to run your first Tigres Program. We will run the tasks as threads by passing
EXECUTION_LOCAL_THREAD as the execution plugin.:
$ source $VIRTUALENV_HOME/envtigres/bin/activate
(envtigres)$ python hello_world_parallel.py \
EXECUTION_LOCAL_THREAD
The output will looking similar to the following:
++++++++++++++++++++++++++++
Initial Input:
GdkknShfqdrvnqkc
++++++++++++++++++++++++++++
++++++++++++++++++++++++++++
Final Output:
Hello Tigres world!
++++++++++++++++++++++++++++
The Final Output you see is the decoded message, “Hello Tigres world!”. Two output files are produced HelloWorldParallel.dot
and hello_world_parallel.log:
$ ls
HelloWorldParallel.dot hello_world_parallel.log hello_world_parallel.py
The dot file which is discussed in the next section is a graph representation of the executed workflow.
The log file is the detailed log of the Tigres workflow. The examples in this tutorial will detail how to write
to the Tigres log, check the status of your workflow and query the logs for special information.
The next several sections will walk though hello_world_parallel.py.
Load Tigres API¶
In lines 7-8 the Tigres API is loaded into the python program namespace.
Line 7 imports all functions and classes from tigres while line 8
imports the tigres.utils.Execution, tigres.utils.TigresException and tigres.utils.State.
from tigres import *
from tigres.utils import Execution, TigresException, State
The main Function¶
The main function has some boiler plate code that is run before and after any templates are executed.
def main(execution):
# Setup up the Tigres Program using __file__ to build the log file name
start(log_dest=os.path.splitext(__file__)[0] + '.log', execution=execution)
# Set the logging level
set_log_level(Level.INFO)
# Heart of Tigres Program here
# Create DOT (plain text graph) file
dot_execution()
# End the Tigres Program
end()
Program initialization¶
Before any templates are executed, the Tigres program is initialized with a call
to start(). This function configures and initializes the Tigres program. In the above code,
the program specifies the log file name (log_dest) as well as the execution
mechanism (e.g. execution='EXECUTION_LOCAL_THREADS').
The function start() will end a previously started Tigres program. The
verbosity of the logs is set using set_log_level(). After this call,
all messages at a numerically higher level (e.g. DEBUG if level is INFO) will be skipped
(See Level).
Graph visualization¶
After the last template is executed, the execution can be visualized using
dot_execution(). This function creates a DOT file (plain text graph)
for a visual representation of the completed workflow. The function
dot_execution() writes a graph file of the current
Tigres execution workflow that can be visualized using the
visualization tools of your choice
such as GraphViz. Lastly, the Tigres program is finalized
with a call to end().
The __main__ Driver¶
The driver program at the bottom of the file, does some argument checking,
executes main() and prints any raised errors. If a tigres.utils.TigresException
is raised, the message is printed and then the monitoring information is checked for more
detailed error messages using tigres.check(). Line 26, searches the monitoring information
for the currently running program for all Tigres tasks that have a state of State.FAIL.
if __name__ == "__main__":
# Simple Usage Here
if len(sys.argv) <= 1:
print("Usage: {} ({})>".format(sys.argv[0], "|".join(Execution.LOOKUP.keys())))
exit()
try:
main(Execution.get(sys.argv[1]))
except TigresException as e:
print(e)
task_check = check('task', state=State.FAIL)
for task_record in task_check:
print(".. State of {} = {} - {}".format(task_record.name, task_record.state, task_record.errmsg))
The Decode Function¶
A function named decode() is defined. This function takes a single character value and decodes it
by adding one to its ASCII value. The second to last line adds some debugging code. If the logging level
is set to DEBUG, then the specified keyword value pairs will be written to the logs.
def decode(value):
if isinstance(value, int):
ordinal = value
else:
ordinal = ord(str(value))
ordinal += 1
log_debug("decode", message="{} to {}".format(value, unichr(ordinal)))
return unichr(ordinal)
The workflow¶
In this section we will describe the main components of the Tigres program, hello_world_parallel.py.
Start at line 27 after the declaration of hidden_message.
Decode Task¶
Lines 27-29 creates a task. The instantiated tigres.Task uses the decode function as its
execution. The first parameter names the Task "Decode". If the name is None then a unique
name will be chosen by the Tigres framework. The second parameter declares this a task of type FUNCTION
which means that a python function will be the third parameter. The other option is EXECUTABLE in which
case a string representing an executable program (e. g. “wget”, “my_c_program”) would be specified. The decode
function is passed as third parameter. The last parameter,
input_types, defines the function arguments. It is an ordered list of data types.
# Create Decode Tigres Task
task_decode = Task("Decode", FUNCTION, impl_name=decode, input_types=[str])
Lines 30-32 create a tigres.TaskArray named “Decode Tasks”.
# Create a TaskArray with one our one decode task
task_array = TaskArray('Decode Tasks', tasks=[task_decode])
Decode Input¶
Line 33-35 defines what the input to the workflow is. Line 34 instantiates an empty
tigres.InputArray named “Coded Values”.
# Create a Tigres InputArray of the character values to decode
input_array = InputArray("Coded Values", [])
Lines 36-40 iterates over the hidden message string and instantiates an tigres.InputValues()
for each character in the string. Each InputValues is appended to input_array
created on line 40.
# Iterate through the message string and add input values for each character
for c in hidden_message:
input_values = InputValues("A Coded Value {}".format(c), [c])
input_array.append(input_values)
Parallel Template¶
Line 42 has the call to tigres.parallel() which runs the decode function in parallel. The parallel
template is named “Fast Decoding” and is passed the previously created task_array and input_array.
The parallel template returns a python list. Each item in the list is the output from a parallel “Decode”
task. Remember only one task was created but it was executed for each InputValues in the InputArray.
# Run the Tigres Parallel template
output = parallel('Fast Decoding', task_array, input_array)
# Check the logs for the decode event
log_records = query(spec=["event = decode"])
for record in log_records:
print(".. decoded {}".format(record.message))
The final section of the code above uses the monitoring function query() to look for the log records written in
the decode function. It searches for the keyword/value pair event = decode. However, this will
only be logged when set_log_level(Level.DEBUG) (see below).
DEBUG Output
.. decoded G to H
.. decoded d to e
.. decoded k to l
.. decoded k to l
.. decoded n to o
.. decoded to
.. decoded S to T
.. decoded h to i
.. decoded f to g
.. decoded q to r
.. decoded d to e
.. decoded r to s
.. decoded to
.. decoded v to w
.. decoded n to o
.. decoded q to r
.. decoded k to l
.. decoded c to d
.. decoded to !
Note
The task_array has one value while the input_array has many. The parallel
template will interpret this as: Run the task named “Decode” for each input value in the input_array.
Finally, in line 54, the output list of the parallel template is converted to a string and written to standard output.
# Print the output
print("\n++++++++++++++++++++++++++++")
print("Final Output:")
print(''.join(output))
print("++++++++++++++++++++++++++++")
Note
The tigres.parallel() template returns a python list and it must be transformed to a string in order to read
the decoded message.
Sequence¶
(a sequence template example)
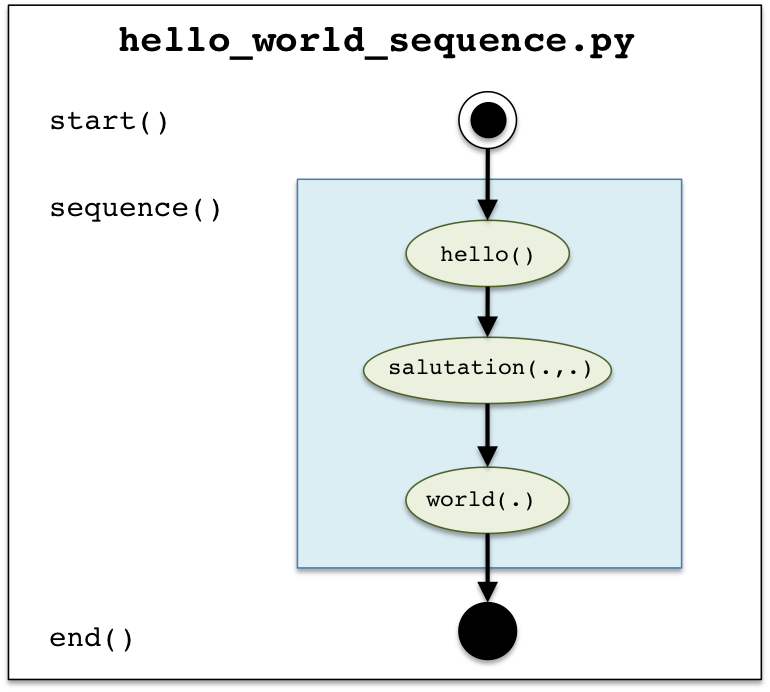
The next example will use a tigres.sequence() template which has data dependencies. The data dependencies will be defined
using the most basic form of tigres.PREVIOUS syntax. The full source example
(hello_world_sequence.py)
can be found in the zip file here.
This example builds the string "Hello Tigres world!" using sequence() with three tasks. The
figure to the left represents the Tigres program hello_world_sequence.py.
The arrows represent execution path and data dependencies. The first task runs hello()
with no inputs. The second task in the sequence executes salutation() and it uses the output of hello() as its
first input value. The third and last task invokes world() and takes the output of salutation() as input.
Download hello_world_sequence.py, to the machine you will be running your
Tigres programs on. You will execute the tasks as processes by passing EXECUTION_LOCAL_PROCESS as the execution plugin.:
$ source $VIRTUALENV_HOME/envtigres/bin/activate
(envtigres)$ python hello_world_sequence.py \
EXECUTION_LOCAL_PROCESS
The output you see will look something like the following:
++++++++++++++++++++++++++++
Initial Input:
None
++++++++++++++++++++++++++++
++++++++++++++++++++++++++++
Final Output:
Hello Tigres World!
++++++++++++++++++++++++++++
Two output files are produced HelloWorldSequence.dot
and hello_world_sequence.log:
$ ls
HelloWorldSequence.dot hello_world_sequence.log hello_world_sequence.py
The dot file is a graph representation and the log file is the detailed log of the Tigres workflow.
The next several sections will walk though hello_world_sequence.py.
The Task Implementations¶
The sequence workflow has three tasks with three separate implementations. As mentioned previously, the implementations
are python functions.
hello¶
The first function is very simple it takes no inputs and returns the string "Hello". This is the
first task in the workflow.
def hello():
"""
:return: Hello
:rtype: str
"""
log_trace('input', function='hello', message='No inputs')
output = "Hello"
log_trace('output', function='hello', message=output)
return output
salutation¶
The second function takes two string inputs and returns a personalized greeting. This is the second task in the workflow
def salutation(greeting, name):
"""
:param greeting: A greeting
:param name: The name to greet
:return: personalized greeting or salutation
"""
log_trace('input', function='salutation', message='greeting={}, name={}'.format(greeting, name))
output = "{} {}".format(greeting, name)
log_trace('output', function='salutation', message=output)
return output
world¶
The third and final function task takes one string as input and returns the “Hello world” string. This is the last task in the workflow.
def world(salutation):
"""
:param salutation: a greeting
:return: Greeting to the world
"""
log_trace('input', function='world', message='salutation={}'.format(salutation))
output = "{} World!".format(salutation)
log_trace('output', function='world', message=output)
return output
The Workflow¶
Initialize the TaskArray and InputArray¶
Lines 63 through 67 add an empty
TaskArray as well as an empty InputArray. They are populated later with
the tasks and input values.
# Create a TaskArray
task_array = TaskArray('Hello World Tasks')
# Create an InputArray
input_array = InputArray("Hello World Inputs")
Hello Task¶
In lines 68-70, the first task is named "Hello" and assigned hello() as its implementation. This is appended to the
task_array thus making it the first task in the sequence. Since the task function does not take any inputs no
input_types are assigned to the task. However, an empty list must be appended to the input_array.
# The Hello Task and its inputs
task_array.append(Task("Hello", FUNCTION, impl_name=hello))
Warning
Order is important for task_array and input_array. The i th task in the task array is matched with the i th input in the input array.
Salutation Task¶
In line 74, the second task after "Hello" is named "Salutation" and assigned salutation() as its implementation.
This is appended to the task_array making it the second task in the sequence workflow. Since this task takes
two string inputs, input_types will be set to [str,str] which signifies that the first and second arguments
to salutation are both strings.
# The Salutation Task and its inputs
task_array.append(Task("Salutation", FUNCTION, impl_name=salutation, input_types=[str, str]))
Line 75 defines the inputs to salutation(greeting, name). The first input is from the "Hello"
task and the second will be the string literal, "Tigres". The output from the "Hello" task is specified
as the first argument with PREVIOUS. This says, “Get the output of the task that was executed previous
to this one and use it as the first input”.
input_array.append([PREVIOUS, "Tigres"])
World Task¶
The final task in lines 76 through 78, named "World", is assigned world() as its implementation.
It takes one string as input from the previous "Salutation" task.
# The World Task and its inputs
task_array.append(Task("world", FUNCTION, impl_name=world, input_types=[str]))
input_array.append([PREVIOUS])
Sequence Template¶
Lines 80-91 has the call to tigres.sequence() which runs the sequence template. It is named
“Hello World” and passed in the previously created task_array and input_array.
# Run the Tigres Sequence template
output = sequence('Hello World', task_array, input_array)
# Check the logs for the decode event
log_records = query(spec=["{} ~ .*put".format(Keyword.EVENT)])
for record in log_records:
print(".. function: {}, {}: {}".format(record["function"], record.event, record.message))
The final section of the code above uses the monitoring function query() to look for the log records written in
the task functions. It searches for records matching the following condition: event ~ .*put. The ~
symbol compares the string value, event , with the regular expression .*put and returns all matches.
However, this will only be logged when set_log_level(Level.TRACE) (see below).
TRACE Output
.. function: hello, input: No inputs
.. function: hello, output: Hello
.. function: salutation, input: greeting=Hello, name=Tigres
.. function: salutation, output: Hello Tigres
.. function: world, input: salutation=Hello Tigres
.. function: world, output: Hello Tigres World!
Finally, the output is written to standard output (Line 96).
# Print the output
print("\n++++++++++++++++++++++++++++")
print("Final Output:")
print(output)
print("++++++++++++++++++++++++++++")
Split and Merge¶
(a example using split and merge templates)
This last example covers both the tigres.split() and
tigres.merge() templates and how to take advantage of the implicit data dependency mechanism
between tasks in Tigres. The full source of the program
(hello_world_split_merge.py) can be found in the zip file
here.
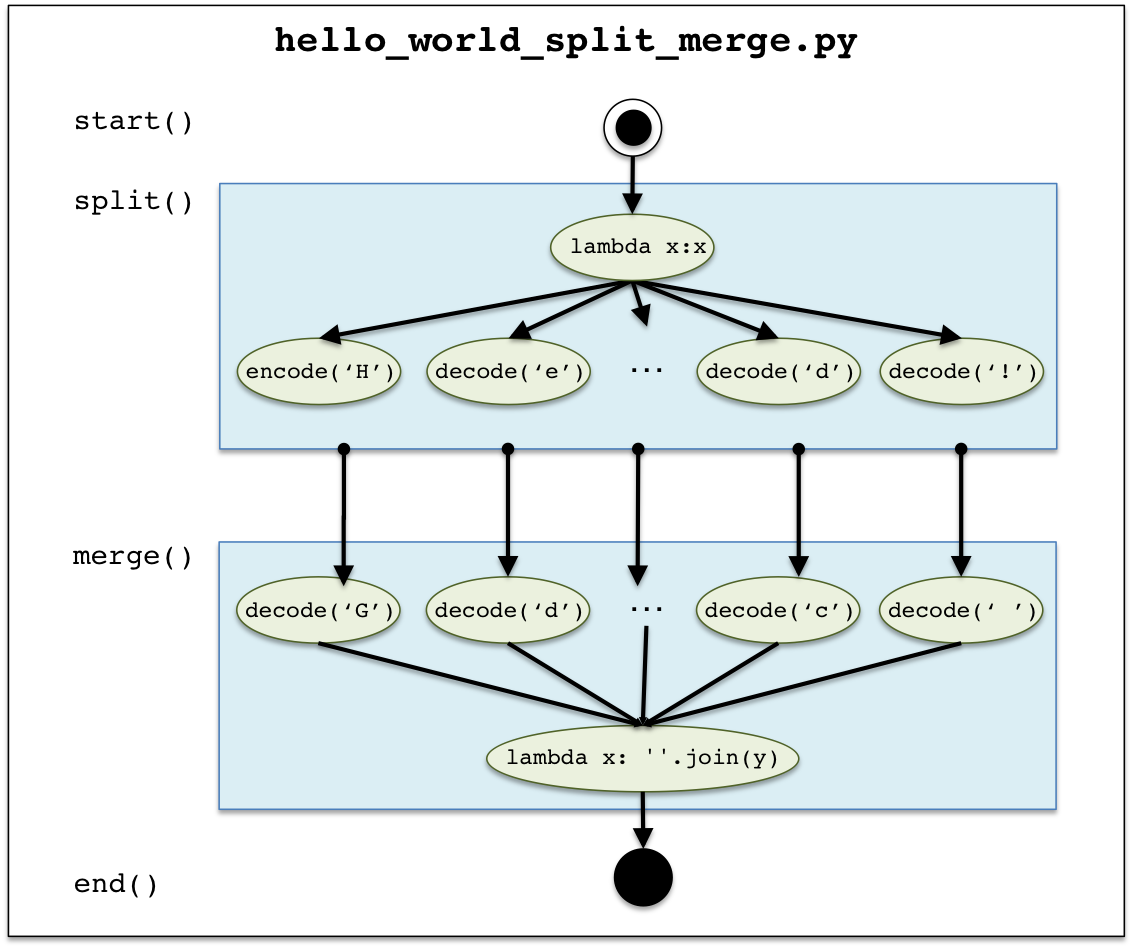
This example is based on the Parallel example. Instead of decoding a hidden message, it
takes a clear-text message, "Hello World Tigres!", encodes it using a tigres.split() template and then
decodes it using a tigres.merge() template. The figure to the right represents the Tigres program
hello_world_split_merge.py. Notice that there are two
(blue) rectangles representing the use of two Tigres templates. The first one is split() and the latter merge().
The arrows show the execution path and data dependencies. Also, there are additional task
implementations. In addition to decode() from the Parallel example, encode() and two lambda
functions have been added.
Download hello_world_split_merge.py, to the machine you will be running your
Tigres programs on. You will execute the tasks as processes by passing EXECUTION_LOCAL_PROCESS as the execution plugin.:
$ source $VIRTUALENV_HOME/envtigres/bin/activate
(envtigres)$ python hello_world_split_merge.py \
EXECUTION_LOCAL_PROCESS
The output you see will look something like the following:
++++++++++++++++++++++++++++++++++++++++++++++++++++++++
Initial Input:
Hello Tigres world!
++++++++++++++++++++++++++++
++++++++++++++++++++++++++++
Intermediate Output:
[u'G', u'd', u'k', u'k', u'n', u'\x1f', u'S', u'h', u'f', u'q', u'd', u'r', u'\x1f', u'v', u'n', u'q', u'k', u'c', u' ']
++++++++++++++++++++++++++++
++++++++++++++++++++++++++++
Final Output:
Hello Tigres world!
++++++++++++++++++++++++++++
Two output files are produced HelloWorldSplitMerge.dot
and hello_world_split_merge.log:
$ ls
HelloWorldSplitMerge.dot hello_world_split_merge.log hello_world_split_merge.py
The dot file is a graph representation and the log file is the detailed log of the Tigres workflow.
The next several sections will walk through hello_world_split_merge.py.
The Task Functions¶
This encode() function takes a character, subtracts one from the ASCII value and returns the new ASCII character.
def encode(value):
if isinstance(value, int):
ordinal = value
else:
ordinal = ord(str(value))
ordinal -= 1
log_debug("encode", message="{} to {}".format(value, unichr(ordinal)))
return unichr(ordinal)
This decode() function takes a character, adds one from the ASCII value and returns the new ASCII character.
def decode(value):
if isinstance(value, int):
ordinal = value
else:
ordinal = ord(str(value))
ordinal += 1
log_debug("decode", message="{} to {}".format(value, unichr(ordinal)))
return unichr(ordinal)
Encoding using a Split Template¶
The string "Hello Tigres World!" is encrypted in lines 26 through 54 of hello_world_split_merge.py (see below).
This function uses a split template. In a split template, a single task (split task) and it’s corresponding inputs as well as a
task array and its corresponding input array are required. The split task is executed first and prepares the inputs for the
task array that executes tasks in parallel after the split task is finished.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# ########################################################
# Setting up a Split Template for encoding the message
#########################################################
# Create a Task for parsing the string
task_to_list = Task("String to List", FUNCTION,
impl_name=lambda x: x, input_types=[str])
input_string = InputValues("String to encode", [message])
# Create a Task Array for the encode_string tasks
task_encode = Task("Encode", FUNCTION, impl_name=encode, input_types=[str])
task_array_encode = TaskArray('Encoding Tasks', tasks=[task_encode])
# We create an empty input array that will be implicitly filled with the
# PREVIOUS task's output. The output of the of the split task must be iterable
input_array_encode = InputArray("String Values", [])
tmpoutput = split("Fast Encoding", task_to_list,
input_string, task_array_encode, input_array_encode)
# Print the output
print("\n++++++++++++++++++++++++++++")
print("Intermediate Output:")
print(tmpoutput)
print("++++++++++++++++++++++++++++\n")
|
- Lines 6-8 above create the split task and its input. The task is defined as a python function that takes a string.
Notice here that a
lambdafunction is used for the implementation. It simply returns the given input. No special processing of the string is necessary. The idea it to use the split template’s implicit ability to split a generator object (i.e.list) into N parallel tasks. - Lines 11-12 create the task array and its task definition. Here only one task
"Encode"is specified withencode()as its implementation. This is because the split template semantics will determine how many copies of this task will be run at execution time from the input string. - Line 16 specifies and empty input array. This tells the split template to go ahead and determine the input from the split task output.
- Finally, Lines 17 and 18 execute the split template named
"Fast Encoding"
Decoding using a Merge Template¶
In lines 56 through 85 of hello_world_split_merge.py, the results of the split() template will be decoded by
the merge() template. In a merge template, a single task (merge task) and it’s corresponding inputs as well as a
task array and its corresponding input array are required.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | #########################################################
# Setting up a Merge Template for decoding the message
#########################################################
# Create Decode Tigres Task
task_decode = Task("Decode", FUNCTION, impl_name=decode, input_types=[str])
# Create a TaskArray with one our one decode_string task
task_array = TaskArray('Decoding Tasks', tasks=[task_decode])
# Run the Tigres Split template
output = merge('Fast Decoding', task_array, None,
Task("To String", FUNCTION, impl_name=lambda x: ''.join(x)))
# Print the output
print("\n++++++++++++++++++++++++++++")
print("Final Output:")
print output
print("++++++++++++++++++++++++++++\n")
log_records = query(spec=["event ~ ..code"])
for record in log_records:
print(".. {}d {}".format(record.event, record.message))
# Create DOT (plain text graph) file
dot_execution()
|
Three statements are executed:
- Line 6 creates a
"Decode"task withdecode()as its implementation - Line 8 creates a task array with one task definition because merge will determine the number of
decodetasks to execute. - Lines 10 and 11 is the execution of the merge template.
Noneis passed in for the input array (line 47) to invoke implicit data dependency between the split and merge templates. The merge template will try to get the results from the previously executed template. The merge task python implementation is alambda()function that joins the characters into a single string. No input values are specified. The merge template will attempt to retrieve the results from the execution of the task array. - Line 16, the output list of the
paralleltemplate written to standard output. - Line 19-21 uses the monitoring function
query()to look for the log records written in the task functions. It searches for records matching the following condition:event ~ .*put. The~symbol compares the string value,event, with the regular expression.*putand returns all matches. However, this will only be logged whenset_log_level(Level.DEBUG)(see below).
DEBUG Output:
.. encoded H to G
.. encoded e to d
.. encoded l to k
.. encoded l to k
.. encoded o to n
.. encoded to
.. encoded i to h
.. encoded T to S
.. encoded g to f
.. encoded r to q
.. encoded e to d
.. encoded s to r
.. encoded to
.. encoded w to v
.. encoded o to n
.. encoded r to q
.. encoded l to k
.. encoded d to c
.. encoded ! to
.. decoded G to H
.. decoded d to e
.. decoded k to l
.. decoded k to l
.. decoded n to o
.. decoded to
.. decoded S to T
.. decoded h to i
.. decoded f to g
.. decoded q to r
.. decoded d to e
.. decoded r to s
.. decoded to
.. decoded v to w
.. decoded n to o
.. decoded q to r
.. decoded k to l
.. decoded c to d
.. decoded to !

{kind=link}